J’ai donc fait un nouveau graphique, du nombre de mort par tranche d’age avec les données de l’INSEE. (Tranche de 10 ans)
Le graphique est faux sur la fin 2020, il ne sera juste que vers mi-fevrier 2021. Quand l’INSEE aura publié les données.
Voici donc mon process :
Etape 1 : Téléchargement des données de l’INSEE : https://www.insee.fr/fr/information/4190491
Etape 2 : je mets tout sur un même fichier:
# cat deces-* Deces_2020_M* | grep -v "nomprenom" > Full.csv
# wc -l Full.csv
25528867 Full.csvEtape 3 : Je fais tourner un premier programme en Python :
J’ai donc obtenu ce graphique :
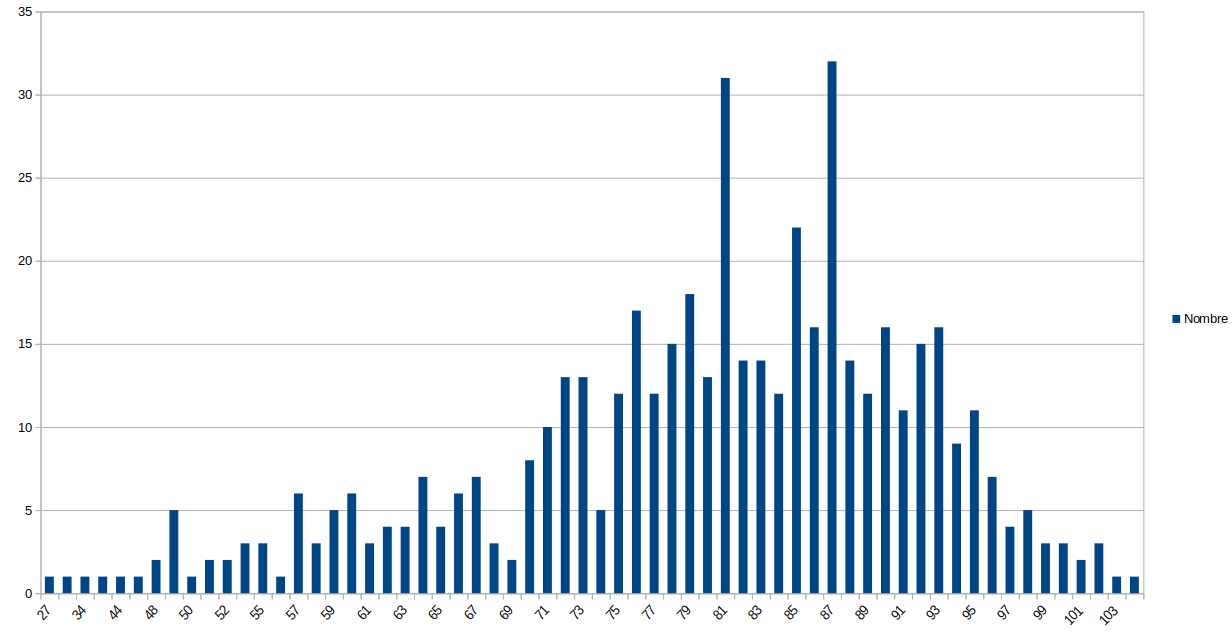 Le record est donc de 105 ans pour MARIE JEANNE.
Le record est donc de 105 ans pour MARIE JEANNE.
Le nombre de décès par mois sur Biot :
| 2017 | 2018 | 2019 | 2020 | |
|---|---|---|---|---|
| Janvier | 5 | 3 | 4 | 4 |
| Février | 0 | 2 | 5 | 3 |
| Mars | 2 | 5 | 3 | 3 |
| Avril | 7 | 7 | 2 | 2 |
| Mai | 4 | 0 | 2 | 1 |
| Juin | 2 | 1 | 2 | 1 |
| Juillet | 7 | 5 | 0 | 1 |
| Aout | 4 | 5 | 1 | 6 |
| Septembre | 2 | 2 | 3 | 2 |
| Octobre | 2 | 5 | 3 | |
| Novembre | 4 | 3 | 5 | |
| Décembre | 3 | 3 | 2 | |
| TOTAL | 42 | 41 | 32 | 23 |
Je crois que j’ai fini d’esploiter les données de l’INSEE.
Voici ce que j’ai obtenu (suite au téléchargement des fichier CSV de l’INSEE voir https://www.cyber-neurones.org/2020/10/insee-fichiers-des-personnes-decedees-depuis-1970/ ) :
| 2017 | 2018 | 2019 | 2020 | |
|---|---|---|---|---|
| Janvier | 1410 | 1325 | 1190 | 1178 |
| Février | 1049 | 1032 | 1143 | 1013 |
| Mars | 1077 | 1146 | 1083 | 1160 |
| Avril | 925 | 953 | 962 | 1073 |
| Mai | 999 | 916 | 933 | 935 |
| Juin | 925 | 908 | 913 | 870 |
| Juillet | 968 | 968 | 1004 | 918 |
| Aout | 953 | 1043 | 964 | 979 |
| TOTAL | 8306 | 8291 | 8192 | 8126 |
| Septembre | 945 | 900 | 1035 | 839 (pas complet) |
| Octobre | 1045 | 1003 | 992 | |
| Novembre | 1043 | 1003 | 1002 | |
| Décembre | 1198 | 1025 | 1113 | |
| TOTAL | 12537 | 12222 | 12334 |
On a bien une augmentation en Mars (+7,11%) et Avril (+11,54%), mais c’est compensé par une diminution en février et juillet. Mais les données sont provisoire, les données seront consolidés 3 ou 4 mois après. Le mieux est donc d’attendre avant de faire des analyses.
J’ai pu voir un faux tableaux sur Facebook : 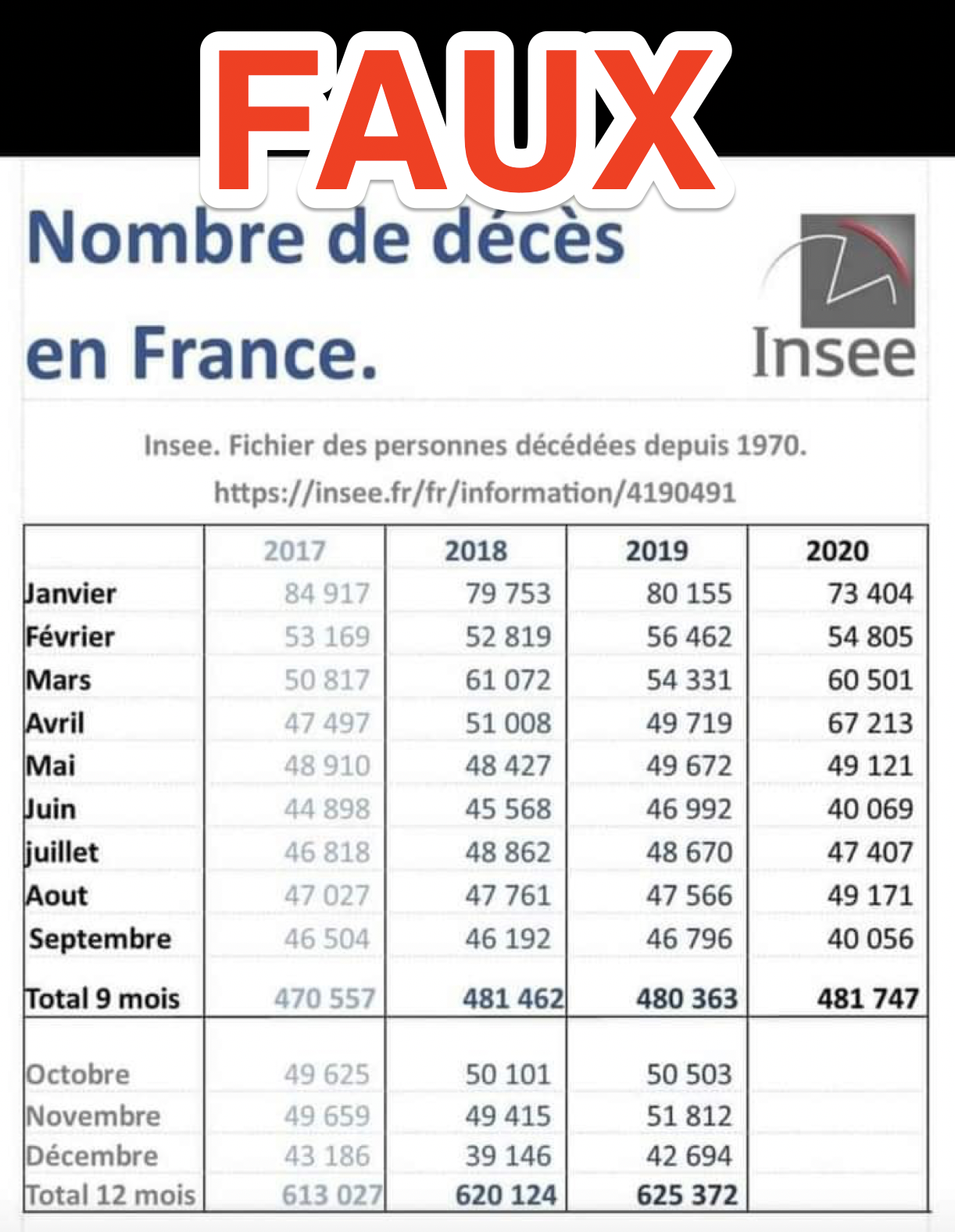 Pourquoi il est faux ? Si je fais un script pour chercher le nombre de mort sur les mois de Janvier :
Pourquoi il est faux ? Si je fais un script pour chercher le nombre de mort sur les mois de Janvier :
sum_201701=0
sum_201801=0
sum_201901=0
sum_202001=0
for entry in *.csv
do
echo "$entry"
cat $entry | grep -v "sexe" | sed 's/""/"-"/g'| awk -F'\";\"' '{print substr($7,1, 6)}' | sort -n | uniq -c | grep "201701" | awk '{print $1}' > temp_201701.dat
current_201701=$(cat temp_201701.dat)
cat $entry | grep -v "sexe" | sed 's/""/"-"/g'| awk -F'\";\"' '{print substr($7,1, 6)}' | sort -n | uniq -c | grep "201801" | awk '{print $1}' > temp_201801.dat
current_201801=$(cat temp_201801.dat)
cat $entry | grep -v "sexe" | sed 's/""/"-"/g'| awk -F'\";\"' '{print substr($7,1, 6)}' | sort -n | uniq -c | grep "201901" | awk '{print $1}' > temp_201901.dat
current_201901=$(cat temp_201901.dat)
cat $entry | grep -v "sexe" | sed 's/""/"-"/g'| awk -F'\";\"' '{print substr($7,1, 6)}' | sort -n | uniq -c | grep "202001" | awk '{print $1}' > temp_202001.dat
current_202001=$(cat temp_202001.dat)
if [ $current_201701 > 0 ]
then
echo "In file $entry (dead 201701) : $current_201701"
let "sum_201701=sum_201701+current_201701"
fi
if [ $current_201801 > 0 ]
then
echo "In file $entry (dead 201801) : $current_201801"
let "sum_201801=sum_201801+current_201801"
fi
if [ $current_201901 > 0 ]
then
echo "In file $entry (dead 201901) : $current_201901"
let "sum_201901=sum_201901+current_201901"
fi
if [ $current_202001 > 0 ]
then
echo "In file $entry (dead 202001) : $current_202001"
let "sum_202001=sum_202001+current_202001"
fi
done
echo "Sum dead 201701 : $sum_201701 "
echo "Sum dead 201801 : $sum_201801 "
echo "Sum dead 201901 : $sum_201901 "
echo "Sum dead 202001 : $sum_202001 "Et si je fais un script pour faire pareil sur le mois de mars :
J’ai donc modifié le programme enfin d’avoir les mêmes dates que le tableaux faux sur facebook :
Voici donc mon programme :
MyDate=("201701" "201702" "201703" "201704" "201705" "201706" "201707" "201708" "201709" "201710" "201711" "201712" "201801" "201802" "201803" "201804" "201805" "201806" "201807" "201808" "201809" "201810" "201811" "201812" "201901" "201902" "201903" "201904" "201905" "201906" "201907" "201908" "201909" "201910" "201911" "201912" "202001" "202002" "202003" "202004" "202005" "202006" "202007" "202008" "202009")
for TheDate in ${MyDate[@]}; do
declare sum_$TheDate=0
done
for entry in *.csv
do
echo "$entry"
for TheDate in ${MyDate[@]}; do
touch temp.dat
cat $entry | grep -v "sexe" | sed 's/""/"-"/g'| awk -F'\";\"' '{print substr($7,1, 6)}' | sort -n | uniq -c | grep $TheDate | awk '{print $1}' > temp.dat
declare current_$TheDate=$(cat temp.dat)
varname=current_$TheDate
varname2=sum_$TheDate
if [ ${!varname} > 0 ]
then
echo "In file $entry (dead $TheDate) : ${!varname}"
let "${varname2}=${!varname2}+${!varname}"
fi
done
done
for TheDate in ${MyDate[@]}; do
varname=sum_$TheDate
echo "Sum dead $TheDate : ${!varname} "
doneVoici donc les données Brutes et le temps pour l’exécution du script :
Le lien est ici : https://www.insee.fr/fr/information/4190491 . Je n’arrive pas à comprendre pourquoi les gens font des statistiques sur 2020 alors que la collecte des données est longue.
Quand je télécharge tous les fichiers et que je redirige sur un seul fichier j’ai :
wc -l *.csv
27007 deces-1970.csv
161020 deces-1971.csv
336009 deces-1972.csv
366041 deces-1973.csv
380603 deces-1974.csv
399310 deces-1975.csv
408884 deces-1976.csv
404775 deces-1977.csv
421033 deces-1978.csv
424987 deces-1979.csv
437857 deces-1980.csv
454545 deces-1981.csv
453263 deces-1982.csv
473523 deces-1983.csv
464104 deces-1984.csv
474632 deces-1985.csv
476864 deces-1986.csv
461802 deces-1987.csv
457905 deces-1988.csv
463082 deces-1989.csv
546888 deces-1990.csv
531676 deces-1991.csv
540833 deces-1992.csv
520435 deces-1993.csv
561327 deces-1994.csv
522052 deces-1995.csv
579008 deces-1996.csv
567669 deces-1997.csv
461461 deces-1998.csv
697193 deces-1999.csv
570495 deces-2000.csv
567112 deces-2001.csv
549494 deces-2002.csv
573623 deces-2003.csv
537817 deces-2004.csv
557036 deces-2005.csv
535114 deces-2006.csv
536333 deces-2007.csv
553113 deces-2008.csv
557242 deces-2009.csv
551016 deces-2010.csv
549116 deces-2011.csv
579983 deces-2012.csv
582619 deces-2013.csv
569446 deces-2014.csv
609628 deces-2015.csv
603320 deces-2016.csv
612927 deces-2017.csv
620124 deces-2018.csv
625373 deces-2019.csv
60585 deces-2020-m01.csv
53708 Deces_2020_M02.csv
57270 Deces_2020_M03.csv
70944 Deces_2020_M04.csv
52008 Deces_2020_M05.csv
47226 Deces_2020_M06.csv
48414 Deces_2020_M07.csv
47579 Deces_2020_M08.csv
25354453 totalSoit 25.354.453 lignes … je vais enfin pouvoir tester MySQL avec une grande base. A noter que je pense que les fichies sont incompléts , j’ai pas retrouvé le nom de mon grand père mort en 1985.