Voici donc les graphiques :

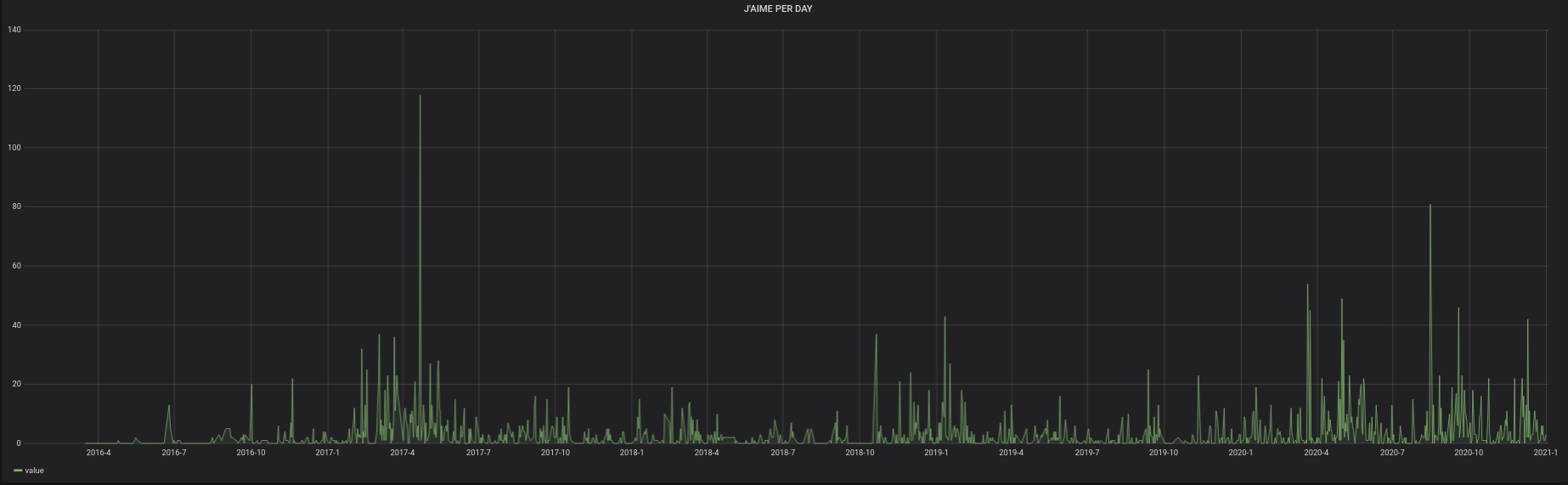
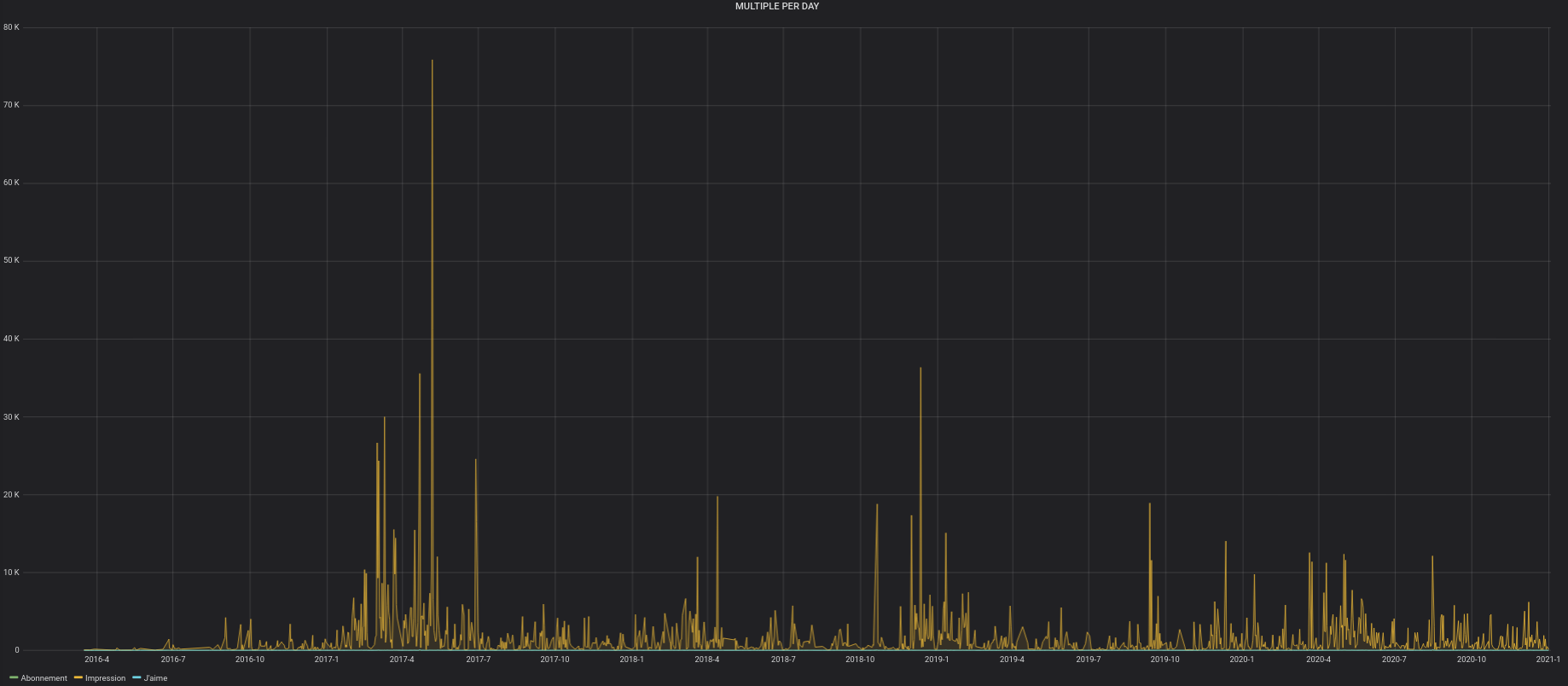

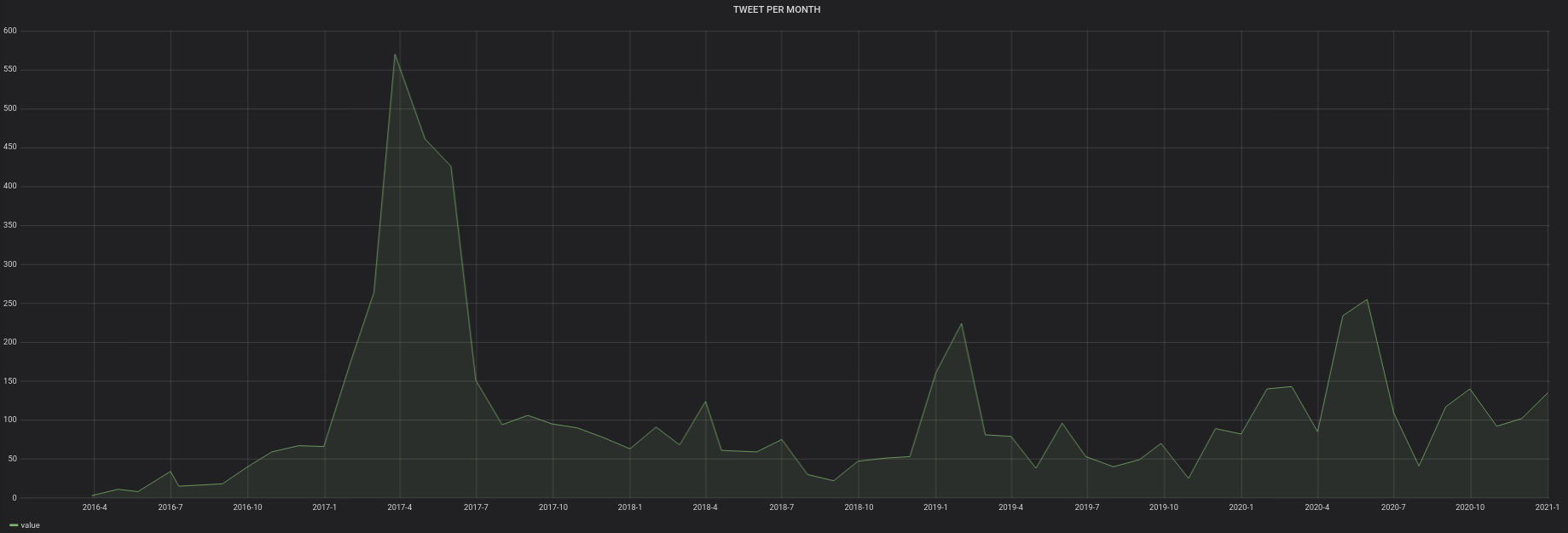
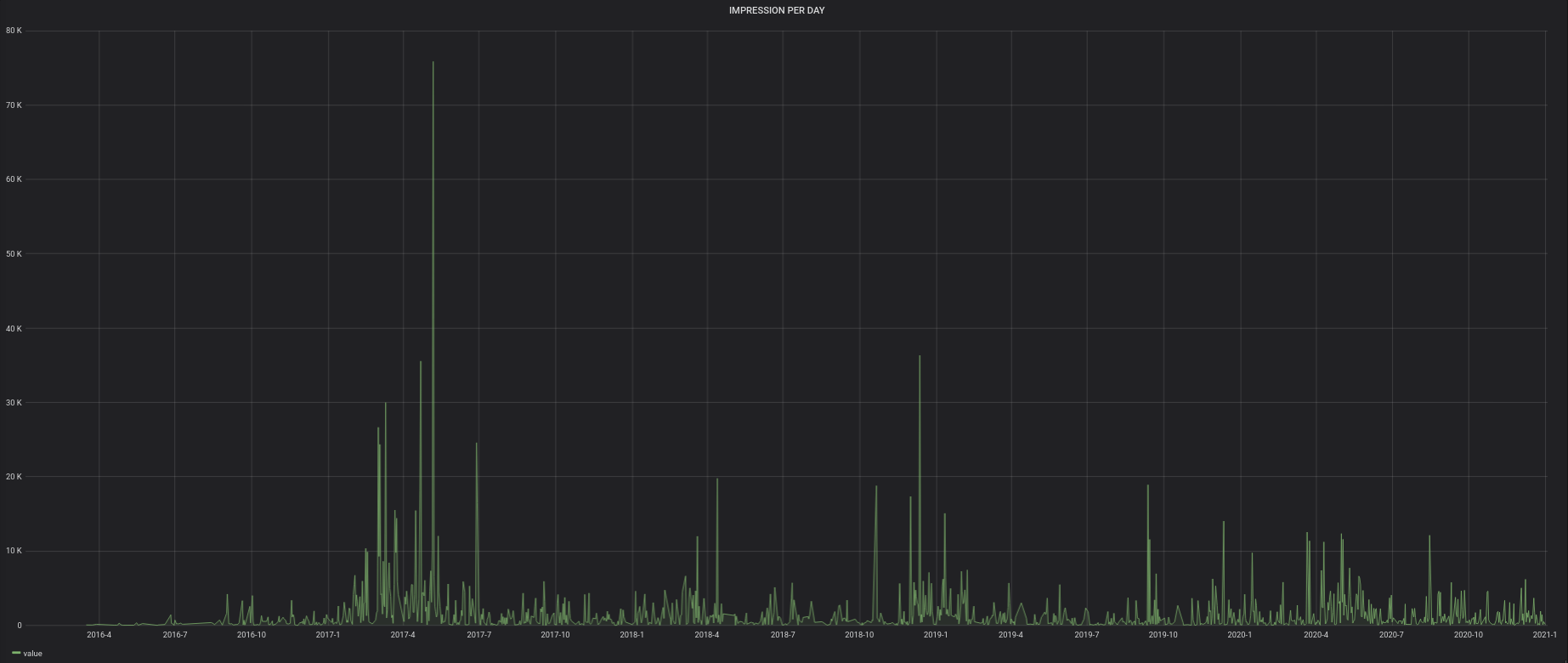 Le programme est en Python.
Le programme est en Python.
J’ai fait un petit script pour envoyer les logs vers Grafana :
mysql -u root -e "CREATE DATABASE TEAMS;"
mysql -u root -e "USE TEAMS;DROP TABLE TEAMS_AUDIT;"
mysql -u root -e "USE TEAMS; CREATE TABLE TEAMS_AUDIT (DATE datetime, duration float, vdiMode int, eventpdclevel int);"
echo "Version 1.0";
mysql -u root -e "USE TEAMS; DELETE FROM TEAMS_AUDIT";
grep "desktop_foreground_duration" ~/.config/Microsoft/Microsoft\ Teams/logs.txt ~/.config/Microsoft/Microsoft\ Teams/old_logs_* | sed 's/:/ /g' | awk '{print $6 "-" $4 "-" $5 " " $7 ":" $8 ":" $9 " " $20 " " $24 " " $26}' | sed 's/,/ /g' | sed 's/Jun/06/g' | sed 's/May/05/g' > /tmp/audit_teams.txt
while read line
do
DATE=$(echo $line | awk '{print $1 " " $2}');
DURATION=$(echo $line | awk '{print $3}');
VDI=$(echo $line | awk '{print $4}');
LEVEL=$(echo $line | awk '{print $5}');
SQL="USE TEAMS; INSERT INTO TEAMS_AUDIT (DATE, duration, vdiMode, eventpdclevel) VALUES ('$DATE',$DURATION,$VDI,$LEVEL);"
#echo $SQL
mysql -u root -e "$SQL"
done < /tmp/audit_teams.txt
echo "Done"Ensuite sur Grafana il suffit de faire :
Je viens de faire un nouveau programme en Python afin de mettre les données de ENEDIS sur MariaDB & Python. Pour avoir les données de ENEDIS il faut aller sur https://mon-compte-particulier.enedis.fr/home-connectee/ et se faire un compte. Puis relier ce compte à la facture EDF … Je vais pas vous mentir c’est un peu de parcours du combattant. J’ai du faire appel à plusieurs fois au support afin que le lien puisse se faire. Misère.
Pour utiliser le script il faut:
Slack permet le téléchargement d’un fichier CSV ( access_logs.csv ), dont les données sont les suivantes :
Petit rappel sur l’ajout d’une database et d’un utilisateur :
$ sudo mysql -u root
MariaDB [(none)]> create database SLACK;
MariaDB [(none)]> CREATE USER 'slack'@'localhost' IDENTIFIED BY 'slack';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON SLACK.* TO 'slack'@'localhost';
MariaDB [(none)]> FLUSH PRIVILEGES;
MariaDB [(none)]> \quit
ByePetit rappel aussi en python pour télécharger une classe non disponible :
Je viens de faire un petit sondage afin de voir les sites utilisés par les professeurs, j’ai ceci :
HOST=“https://www.atrium-sud.fr/" HOST=“https://www.index-education.com/fr/" HOST=“https://eu.bbcollab.com” HOST=“https://www.youtube.com” HOST=“https://sites.google.com” HOST=“https://lycee.cned.fr/login/index.php"
Je vais donc lancer un petit Grafana afin de voir si les sites sont toujours UP.
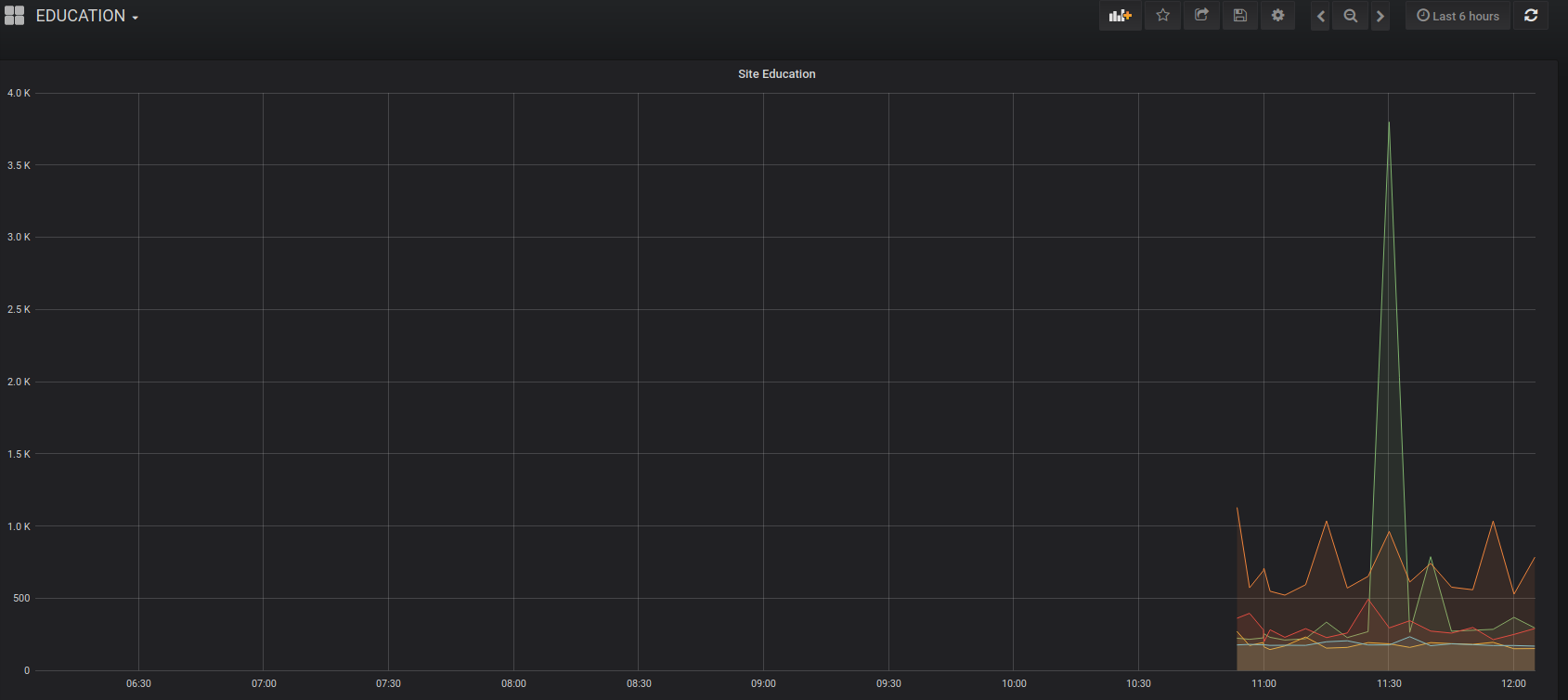 A noter que j’ai du mal à comprendre l’utilisation des sites de Google, cela insite les élèves à se distraire … Misère.
A noter que j’ai du mal à comprendre l’utilisation des sites de Google, cela insite les élèves à se distraire … Misère.
Par exemple si je vais sur PeetTube à la place de Youtube https://joinpeertube.org/fr/ , je peux voir que l’académie de Lyon : https://tube.ac-lyon.fr/ est présente. Je ne vois AUCUNE publicité :
Les prérequis :
Voici donc ce que j’ai fait pour avoir mes données sous Grafana.
Je vais sur Twitter Analytics : https://analytics.twitter.com/about et je télécharge les fichiers CSV (By Tweet, et non By Day). Normalement j’ai un fichier CSV par mois.
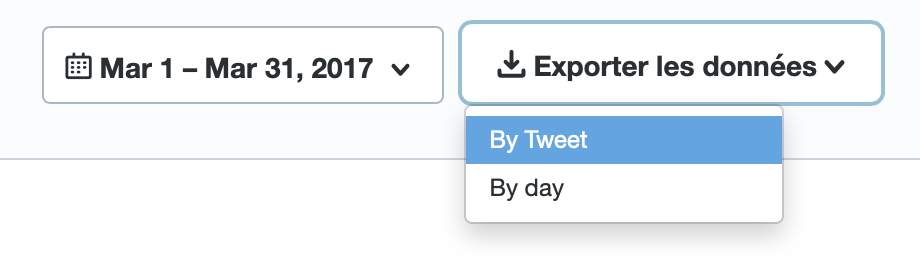
Je concatène tous les fichiers CSV dans un seul fichier en supprimant les entetes :
J’ai fait une version 2 qui permet de voir l’intéraction avec les utilisateurs : les sources sont disponibles ici : https://github.com/farias06/Grafana/blob/master/Twitter_CSV_insert_v2.py )
import csv
from datetime import datetime
import mysql.connector
import re
from mysql.connector import errorcode
from mysql.connector import (connection)
cnx = connection.MySQLConnection(user='twitter', password='twitter',
host='127.0.0.1',
database='TWITTERS')
cursor = cnx.cursor();
now = datetime.now().date();
#cursor.execute("DROP TABLE TWITTER;");
#cursor.execute("CREATE TABLE TWITTER (IDENTIFIANT varchar(30) UNIQUE,PERMALIEN varchar(200),TEXTE varchar(500),DATE datetime,IMPRESSION float,ENGAGEMENT float,TAUX_ENGAGEMENT float, RETWEET float,REPONSE float, JAIME float, CLIC_PROFIL float, CLIC_URL float, CLIC_HASTAG float, OUVERTURE_DETAIL float, CLIC_PERMALIEN float, OUVERTURE_APP int, INSTALL_APP int, ABONNEMENT int, EMAIL_TWEET int, COMPOSER_NUMERO int, VUE_MEDIA int, ENGAGEMENT_MEDIA int);");
#cursor.execute("CREATE TABLE TWITTER_USER (USER varchar(20),IDENTIFIANT varchar(30), DATE datetime, PRIMARY KEY (USER,IDENTIFIANT));");
cursor.execute("DELETE FROM TWITTER_USER")
cursor.execute("DELETE FROM TWITTER");
cnx.commit();
with open('input.csv', 'r') as csvfile:
reader = csv.reader(csvfile, quotechar='"')
for row in reader:
MyDate=row[3].replace(" +0000", ":00")
MyTexte=row[2].replace("'", " ")
MyTexte=MyTexte.replace(",", " ")
MyC4=row[4].replace("Infinity", "0")
MyC5=row[5].replace("Infinity", "0")
MyC6=row[6].replace("Infinity", "0")
MyC6=MyC6.replace("NaN", "0")
MyC7=row[7].replace("Infinity", "0")
User = re.findall(r'(?<=\W)[@]\S*', MyTexte)
for MyUser in User:
try :
cursor.execute("INSERT INTO TWITTER_USER (IDENTIFIANT,USER,DATE) VALUES ('"+row[0]+"','"+MyUser+"','"+MyDate+"');");
except mysql.connector.Error as err:
print("Something went wrong: {}".format(err))
if err.errno == errorcode.ER_BAD_TABLE_ERROR:
print("Creating table TWITTER_USER")
else:
None
try :
cursor.execute("INSERT INTO TWITTER (IDENTIFIANT,PERMALIEN,TEXTE,DATE,IMPRESSION,ENGAGEMENT,TAUX_ENGAGEMENT,RETWEET,REPONSE, JAIME, CLIC_PROFIL, CLIC_URL, CLIC_HASTAG, OUVERTURE_DETAIL, CLIC_PERMALIEN, OUVERTURE_APP, INSTALL_APP, ABONNEMENT, EMAIL_TWEET, COMPOSER_NUMERO, VUE_MEDIA, ENGAGEMENT_MEDIA) VALUES ('"+row[0]+"', '"+row[1]+"', '"+MyTexte+"','"+MyDate+"', "+MyC4+", "+MyC5+", "+MyC6+", "+MyC7+", "+row[8]+","+row[9]+", "+row[10]+", "+row[11]+","+row[12]+","+row[13]+","+row[14]+","+row[15]+","+row[16]+","+row[17]+","+row[18]+","+row[19]+","+row[20]+","+row[21]+");");
except mysql.connector.Error as err:
print("Something went wrong: {}".format(err))
if err.errno == errorcode.ER_BAD_TABLE_ERROR:
print("Creating table TWITTER")
else:
None
cnx.commit();
cursor.close();
cnx.close();Il faut donc faire la requête suivante :
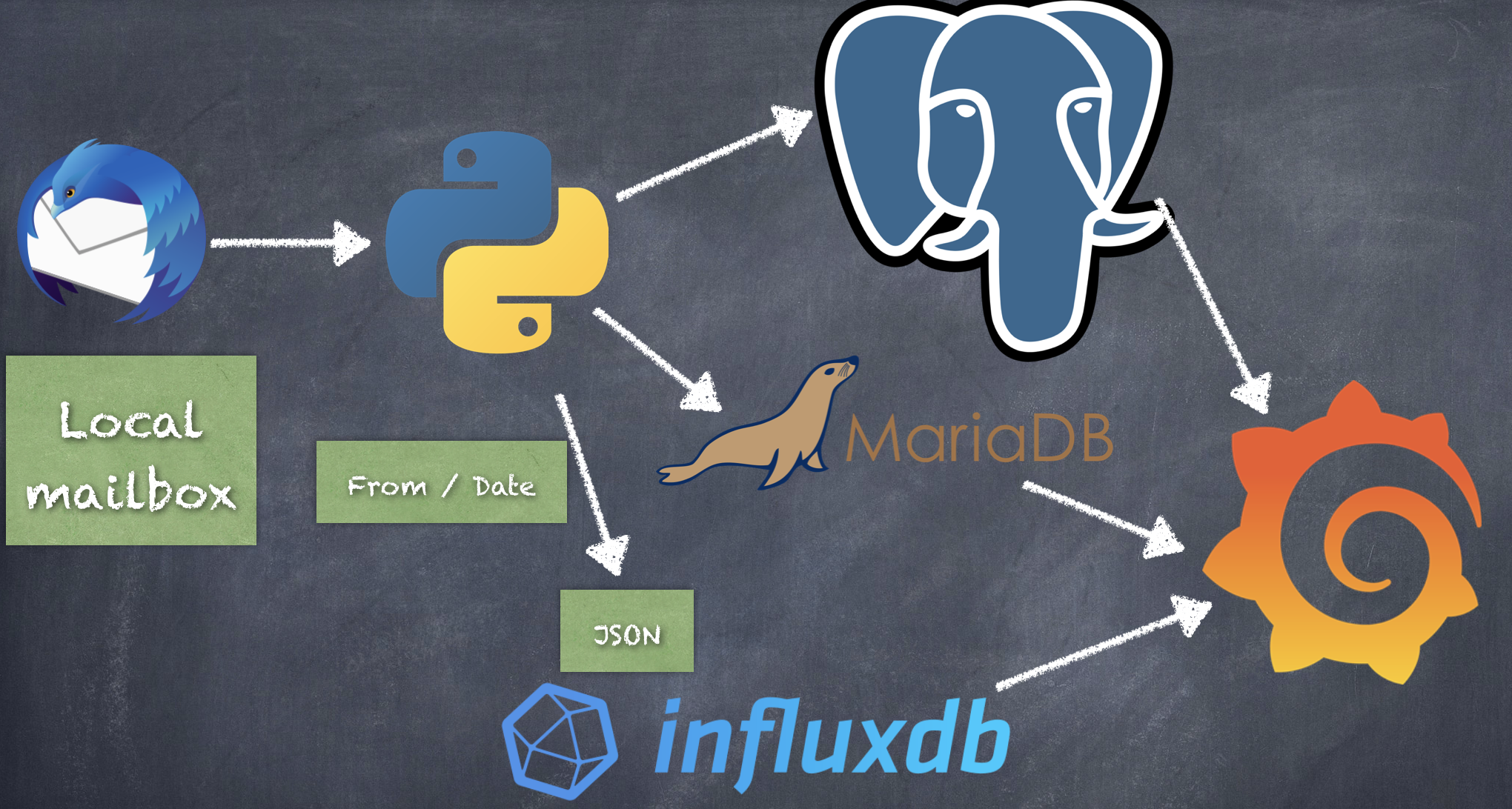
J’ai amélorié ( voir : https://www.cyber-neurones.org/2020/03/thunderbird-mbox-to-influxdb-and-postgresql-to-grafana-in-python/ ) le programme afin d’injecter sur MySQL ( MariaDB en vérité ). Le plus facile a manipuler sur Grafana c’est MariaDB.
Pour se connecter de Grafana à MariaDB :
SELECT
UNIX_TIMESTAMP(date) AS time_sec,
domain as ‘metric’,
count(domain) as value
FROM thunderbird
WHERE
$__timeFilter(date)
GROUP BY DAY(date),MONTH(date),YEAR(date)
ORDER BY date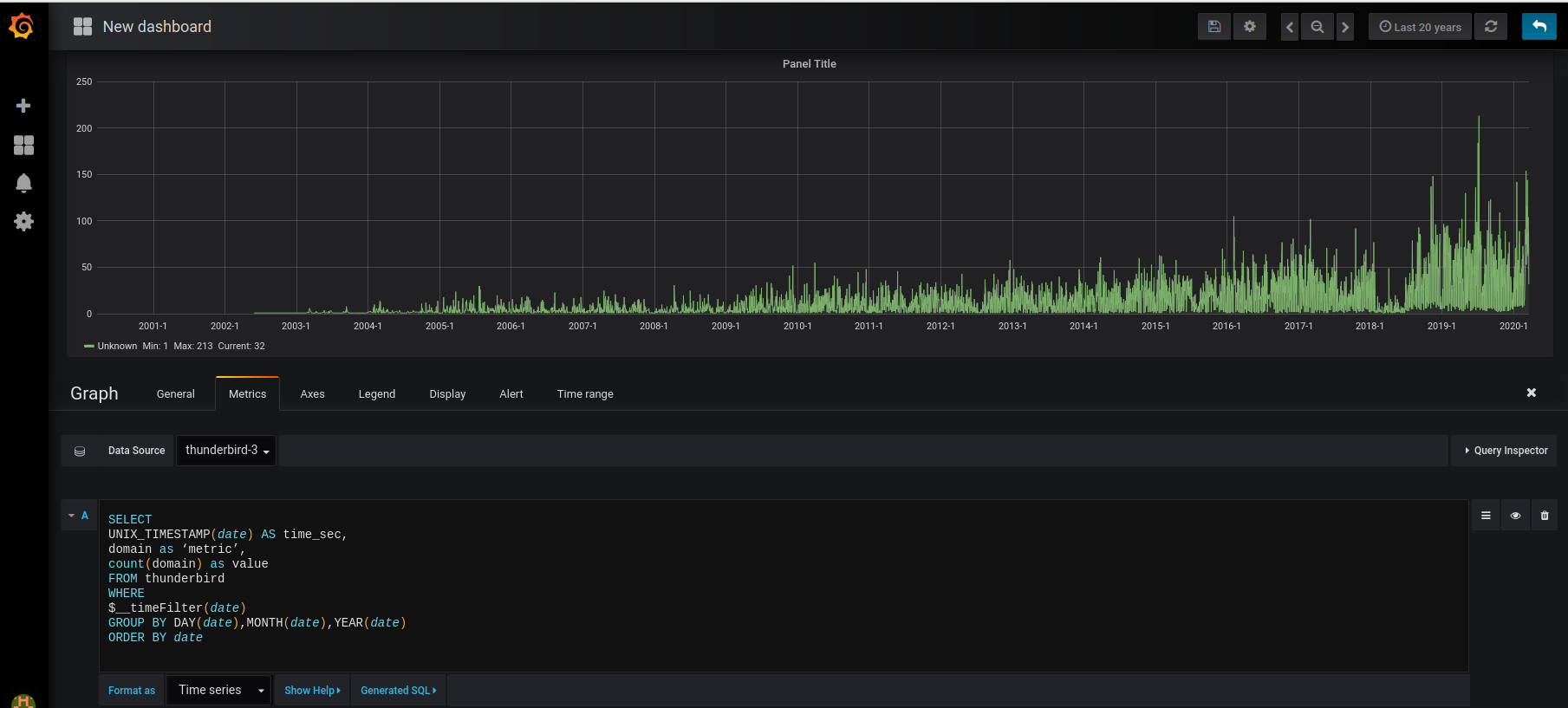 Par mois :
Par mois :SELECT
UNIX_TIMESTAMP(date) AS time_sec,
domain as ‘metric’,
count(domain) as value
FROM thunderbird
WHERE
$__timeFilter(date)
GROUP BY MONTH(date),YEAR(date)
ORDER BY date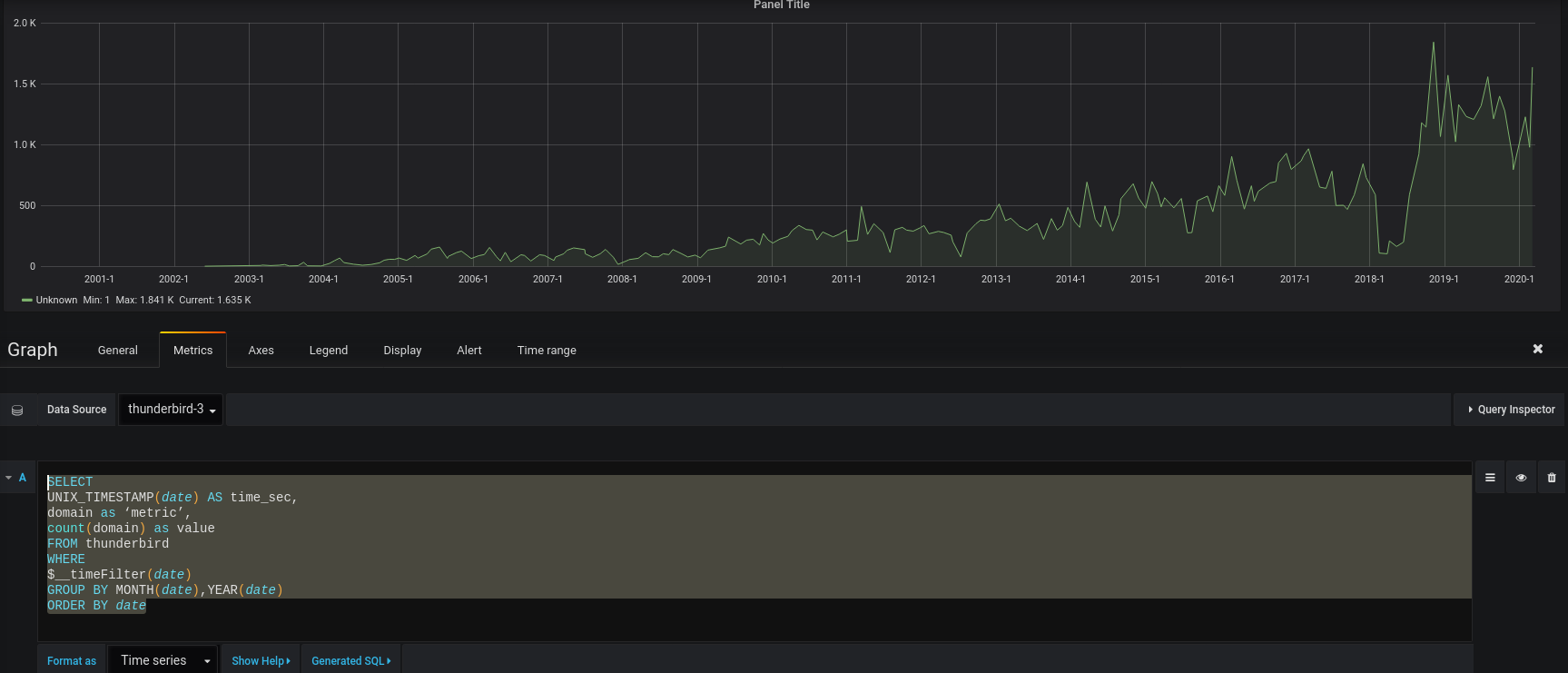 Par années :
Par années :SELECT
UNIX_TIMESTAMP(date) AS time_sec,
domain as ‘metric’,
count(domain) as value
FROM thunderbird
WHERE
$__timeFilter(date)
GROUP BY YEAR(date)
ORDER BY date( Source sur : https://github.com/farias06/Python/blob/master/parse_email_v2.py )
Ma version de MacOS :
$ uname -a
Darwin MacBook.local 19.0.0 Darwin Kernel Version 19.0.0: Thu Oct 17 16:17:15 PDT 2019; root:xnu-6153.41.3~29/RELEASE_X86_64 x86_64Mise à jours de brew ( en mode verbose afin d’avoir plus d’information ) :
$ brew update -v
$ brew -v
Homebrew 2.1.16
Homebrew/homebrew-core (git revision 00c2c; last commit 2019-11-18)
Homebrew/homebrew-cask (git revision 9e283; last commit 2019-11-18)
$ brew install grafana
==> Downloading https://homebrew.bintray.com/bottles/grafana-6.4.4.catalina.bottle.tar.gzAie première erreur :
...
==> Caveats
Bash completion has been installed to:
/usr/local/etc/bash_completion.d
==> Summary
? /usr/local/Cellar/node/13.1.0: 4,591 files, 54.2MB
==> Installing grafana dependency: yarn
xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools), missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrun
Error: An exception occurred within a child process:
CompilerSelectionError: yarn cannot be built with any available compilers.
Install GNU's GCC:
brew install gccPour fixer le problème :