« Vous avez reçu cet email parce que mon équipe big data a analysé vos activités dans Jira, Confluence, Gmail, les chats, les documents, les tableaux de bord et vous a étiqueté comme des employés non engagés et improductifs »

Le lien : https://support.laquadrature.net .
Après ma demande d’un format exploitable, ils sont passés du PDF à Excel. Youpi ! La réponse :
“Les données sont de nouveau toutes disponibles en format tableur, ce jusqu’à octobre 2016. En cas de décalage dans la mise en forme à l’ouverture, l’activation des modifications suffit à rétablir le tout.”
Quel beau métier celui de député : http://www.lefigaro.fr/secteur/high-tech/2016/01/22/32001-20160122ARTFIG00268-les-deputes-votent-en-faveur-d-un-windows-a-la-francaise.php
Pour Delphine Batho, le développement d’un système d’exploitation franco-français permettrait à la France de défendre sa souveraineté numérique. «Le cyberespace est dominé par des oligopoles soumis à un droit étranger, à une souveraineté étrangère», a dit la députée des Deux-Sèvres à l’Assemblée, rejoignant une cohorte d’accusations portées contre les «géants du Web».
Il y a déjà assez d’OS : Windows, Linux avec des 20 versions, Mac OS … je ne sais pas sur quelle planète ils habitent. Et plus avant de faire un OS souverain il serait intelligent de ne pas faire de partenariat avec Windows (Education nationale) mais plutôt de se lancer dans le libre sous Linux. Je sais même pas si Batho connait linux pour dire “Le cyberespace est dominé par des oligopoles soumis à un droit étranger” ….
Je m’attaque donc au troisième fichier disponible, ayant donc connu les inondations à Biot .

Le fichier est donc de 1982 à 2015, d’après moi pour une analyse pertinente il faudrait un fichier de plus de 100 ans ;) . Mais je vais donc faire avec ces 33 ans …
Cette fois je ne vais pas faire le barbare et utiliser awk & sed … je vais faire avec Excel :)
Après avoir pris ce fichier : Réserve parlementaire 
Maintenant je prends ce fichier : Dotation d’action parlementaire (Sénat)

On commence par le fichier CSV, qui est au bon format ! Contrairement au fichier du Parlement on a des points-virgules et non des virgules. Mais je ne suis pas pour autant un adepte de ce format à cause des retours chariots.
$ cat reserve2014.csv | awk -F ";" '{print NF-1 }' | sort -n | uniq -c
84 0
7 2
51 3
51 6
7 7
6105 9Il y a quand même 84+7+51+51+7 = 200 lignes à reprendre. Mais il y a des solutions pour reprendre ceci de façon automatique … awk …
Suite aux nombreux problèmes sur les fichiers, je vais donc essayer de lancer des discussions sur leur site. Pour que cela fonctionne je vais parler d’un seul problème à la dois et je vais aussi ne pas mettre d’email ou d’URL dans le contenu.
Discussion n°1 : Format du fichier JSON
Bonjour, Le fichier JSON est difficile à exploiter, car toutes les données sont mises sur une seule ligne. Pouvez-vous faire en sorte que cela soit comme le fichier JSON de la réserve parlementaire ? Cordialement.
Enfin des données en ligne pour des analyses statistiques : https://www.data.gouv.fr/fr/ . A lire l’article : http://www.lefigaro.fr/secteur/high-tech/2016/01/12/32001-20160112ARTFIG00389-le-gouvernement-accelere-l-ouverture-des-donnees-publiques.php : Le gouvernement accélère l’ouverture des données publiques .
Les premières données que j’ai voulu prendre concerne: Réserve parlementaire . J’ai voulu m’abonner a ce jeu de données :

Il faut ouvrir un compte, j’ai opté pour la création d’un compte via Google, mais ce fut un premier échec :
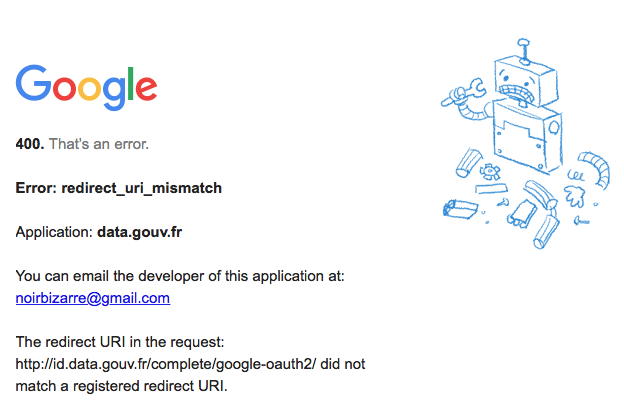
J’ai raté les dates et je n’ai pas pu faire “profiter” de mes idées sur la loi numérique : https://www.republique-numerique.fr .
J’ai pu voir les 9 objectifs de la #LoiNumérique :
J’aurai aimé voir d’autres points dans la #LoiNumérique :