Il suffit de voir :
- Il est en 15 places dans la désinformation.
https://www.20minutes.fr/high-tech/2936119-20201221-sites-publie-plus-intox-coronavirus-france
Ce site partage régulièrement des théories du complot et de fausses informations sur l’actualité internationale, souvent tirées de sites connus pour avoir publié de la propagande et de la désinformation. Par exemple, un article de mars 2020 intitulé « Le coronavirus : produit du hasard ou spécifiquement utilisé comme arme », montre une vidéo du site d’extrême droite suisse Kla.tv, qui relaie souvent des théories du complot.
Après 15 jours de test sur Signal ( https://signal.org/fr/ ) et la migration de beaucoup de comptes vers Signal, je peux dire que Signal est stable.
J’ai testé Signal sous Android (version pour Android : https://play.google.com/store/apps/details?id=org.thoughtcrime.securesms&hl=fr&gl=US ) / Ubuntu : 18.04.5 LTS (Bionic Beaver) / MacOS : Catalina version 10.15.7.
J’ai donc fait un don :
Please keep this email acknowledgment of your donation for your tax records.
Organization: Signal Technology Foundation Campaign: Donate to Signal …. Donation Interval: One-time Receipt #: 10967804 Donated At: 01/15/2021 02:31:30 MST
Pour moi Télégram n’est pas une bonne alternative à WhatsApp ! Idem pour Viber.
Ma séléction :
Il est important de supprimer tous les softs ayant une rapport avec FaceBook. FaceBook c’est simplement le cancer d’internet.
Misère.
How to fix the issue ?
It’s just necessary to rebuild index :
root@my:~# /usr/bin/php /var/www/humhub/protected/yii search/rebuild
Rebuild search index: ..........OK !
root@my:~# /usr/bin/php /var/www/humhub/protected/yii queue/run
root@my:~# /usr/bin/php /var/www/humhub/protected/yii cron/run Frédéric.
Le mieux est de regarder cette vidéo :
Liste des articles de presse :
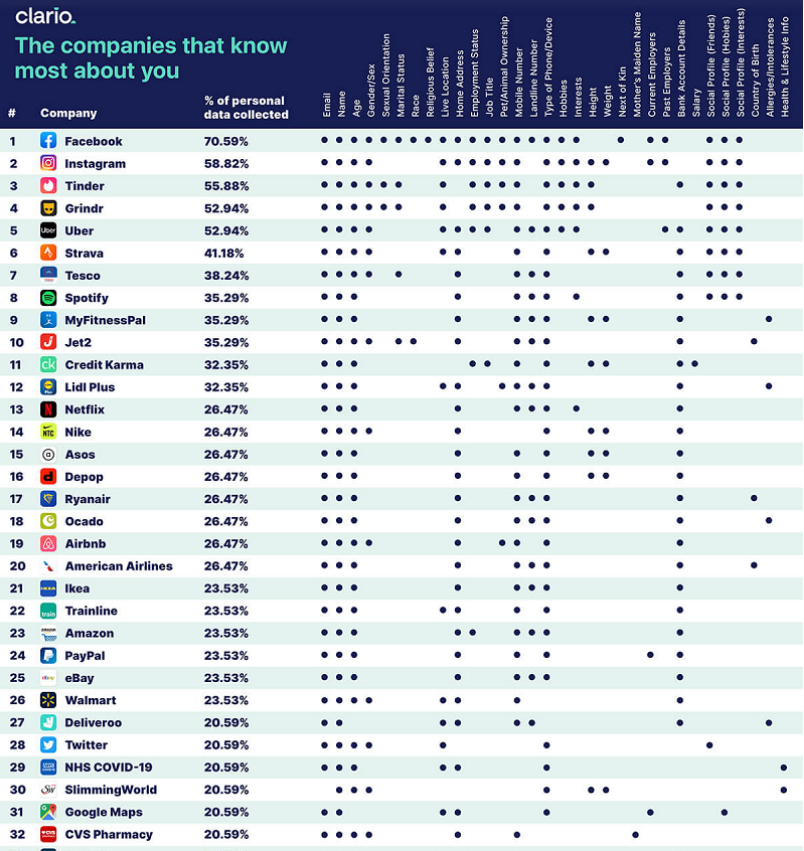
Il faut lire cet article : https://www.socialmediatoday.com/news/the-companies-that-know-the-most-about-you-based-on-app-data-infographic/588161/ : Facebook et Instagram sont de loin les applications qui en savent le plus sur vous.
 Ensuite Facebook est un acteur majeur dans la désinformation : https://www.lefigaro.fr/secteur/high-tech/desinformation-une-etude-pointe-de-nouvelles-failles-chez-facebook-20200430
Ensuite Facebook est un acteur majeur dans la désinformation : https://www.lefigaro.fr/secteur/high-tech/desinformation-une-etude-pointe-de-nouvelles-failles-chez-facebook-20200430
Pour son étude, Newsguard s’est penché sur les pages Facebook francophones suivies par au moins 40.000 internautes et qui ont relayé dix des intox les plus vivaces sur la pandémie (la 5G est liée au coronavirus, la vitamine C ou l’ail permet de s’en protéger, Bill Gates est derrière la pandémie…). Douze pages, gérées depuis la France, la Belgique ou des pays d’Afrique francophone, et réunissant une audience totale de 3,3 millions de personnes, ont été identifiées. Newsguard a retenu un échantillon de vingt posts. Seuls quatre ont été traités par les fact-checkeurs partenaires du réseau social: un avertissement apparaît quand l’internaute tente de les consulter.
MeWe : https://mewe.com/ , semble être une bonne alternative à Google+ . Pour l’instant tout n’est pas traduit mais c’est prometteur. A noter aussi qu’il est possible de faire un import de Google+ vers MeWe. Et sur MeWe il y a 8 Go de gratuit, ensuite il faut payer :

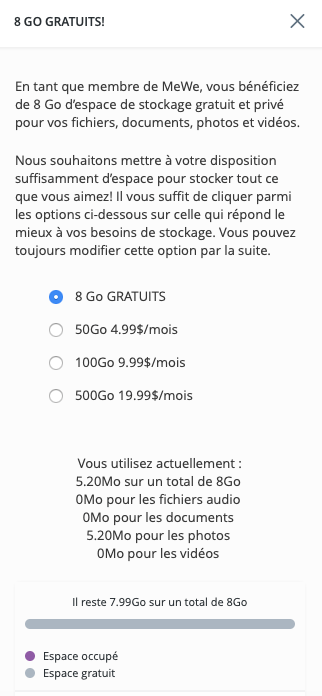
J’espère pouvoir voir un prix à 2 Euros/mois pour 20 Go. Il est aussi possible de récupérer son contenu :
 Pour la migration sur Google+ c’est sur JVC : 50% français / 50% anglais :
Pour la migration sur Google+ c’est sur JVC : 50% français / 50% anglais :
Install JOPLIN : https://joplin.cozic.net , and start REST API.
Step 1 : Download all with https://takeout.google.com
Step 2 : Uncompress and put all on same folder.
Step 3 : Put this script in folder.
Step 4 : Edit the script and put your token
The script :
#
# Version 1
# for Python 3
#
# ARIAS Frederic
# Sorry ... It's difficult for me the python :)
#
from os import listdir
from pathlib import Path
import glob
import csv
import locale
import os
import time
from datetime import datetime
import json
import requests
nb_metadata = 0
nb_metadata_import = 0
def month_string_to_number(string):
m = {
'janv.': 1,
'feb.': 2,
'févr.': 2,
'mar.': 3,
'mars': 3,
'apr.':4,
'avr.':4,
'may.':5,
'mai':5,
'juin':6,
'juil.':7,
'aug.':8,
'août':8,
'sept.':9,
'oct.':10,
'nov.':11,
'déc.':12
}
s = string.strip()[:5].lower()
try:
out = m[s]
return out
except:
raise ValueError('Not a month')
locale.setlocale(locale.LC_TIME, 'fr_FR.UTF-8')
#today = datetime.date.today()
#print(today.strftime('The date :%d %b. %Y à %H:%M:%S UTC'))
from time import strftime,localtime
print(localtime())
print(strftime("%H:%M:%S, %d %b. %Y",localtime()))
date = datetime.strptime('2017-05-04',"%Y-%m-%d")
#Token
ip = "127.0.0.1"
port = "41184"
token = "Put your token here"
nb_import = 0;
headers = {'Content-type': 'application/json', 'Accept': 'text/plain'}
url_notes = (
"http://"+ip+":"+port+"/notes?"
"token="+token
)
url_folders = (
"http://"+ip+":"+port+"/folders?"
"token="+token
)
url_tags = (
"http://"+ip+":"+port+"/tags?"
"token="+token
)
url_ressources = (
"http://"+ip+":"+port+"/ressources?"
"token="+token
)
#Init
GooglePlus_UID = "12345678901234567801234567890123"
UID = {}
payload = {
"id":GooglePlus_UID,
"title":"GooglePlus Import"
}
try:
resp = requests.post(url_folders, data=json.dumps(payload, separators=(',',':')), headers=headers)
resp.raise_for_status()
resp_dict = resp.json()
print(resp_dict)
print("My ID")
print(resp_dict['id'])
GooglePlus_UID_real = resp_dict['id']
save = str(resp_dict['id'])
UID[GooglePlus_UID]= save
except requests.exceptions.HTTPError as e:
print("Bad HTTP status code:", e)
except requests.exceptions.RequestException as e:
print("Network error:", e)
for csvfilename in glob.iglob('Takeout*/**/*.metadata.csv', recursive=True):
nb_metadata += 1
print(nb_metadata," ",csvfilename)
#print("Picture:"+os.path.basename(csvfilename))
mybasename = os.path.basename(csvfilename)
mylist = mybasename.split(".")
myfilename = mylist[0] + "." + mylist[1]
filename = os.path.dirname(csvfilename)+"/"+myfilename
my_file = Path(filename)
with open(csvfilename) as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
if (len(row['description']) > 0):
print(row['title'], row['description'], row['creation_time.formatted'], row['geo_data.latitude'], row['geo_data.longitude'])
#date = datetime.strptime(row['creation_time.formatted'], "%d %b %Y à %H:%M:%S %Z").timetuple()
#print(date)
mylist2 = row['creation_time.formatted'].split(" ");
mylist3 = mylist2[4].split(":");
date = date.replace(hour=int(mylist3[0]), year=int(mylist2[2]), month=month_string_to_number(mylist2[1]), day=int(mylist2[0]))
timestamp = time.mktime(date.timetuple())*1000
print(timestamp)
nb_metadata_import += 1
mybody = row['description']
if (len(row['geo_data.latitude']) > 2):
payload_note = {
"parent_id":GooglePlus_UID_real,
"title":row['creation_time.formatted'],
"source":myfilename,
"source_url":row['url'],
"order":nb_metadata_import,
"body":mybody
}
payload_note_put = {
"latitude":float(row['geo_data.latitude']),
"longitude":float(row['geo_data.longitude']),
"source":myfilename,
"source_url":row['url'],
"order":nb_metadata_import,
"user_created_time":timestamp,
"user_updated_time":timestamp,
"author":"Google+"
}
else:
payload_note = {
"parent_id":GooglePlus_UID_real,
"title":row['creation_time.formatted'],
"source":myfilename,
"source_url":row['url'],
"order":nb_metadata_import,
"user_created_time":timestamp,
"user_updated_time":timestamp,
"author":"Google+",
"body":mybody
}
payload_note_put = {
"source":myfilename,
"order":nb_metadata_import,
"source_url":row['url'],
"user_created_time":timestamp,
"user_updated_time":timestamp,
"author":"Google+"
}
try:
resp = requests.post(url_notes, json=payload_note)
resp.raise_for_status()
resp_dict = resp.json()
print(resp_dict)
print(resp_dict['id'])
myuid= resp_dict['id']
except requests.exceptions.HTTPError as e:
print("Bad HTTP status code:", e)
except requests.exceptions.RequestException as e:
print("Network error:", e)
url_notes_put = (
"http://"+ip+":"+port+"/notes/"+myuid+"?"
"token="+token
)
try:
resp = requests.put(url_notes_put, json=payload_note_put)
resp.raise_for_status()
resp_dict = resp.json()
print(resp_dict)
except requests.exceptions.HTTPError as e:
print("Bad HTTP status code:", e)
except requests.exceptions.RequestException as e:
print("Network error:", e)
if my_file.is_file():
cmd = "curl -F 'data=@"+filename+"' -F 'props={\"title\":\""+myfilename+"\"}' http://"+ip+":"+port+"/resources?token="+token
print("Command"+cmd)
resp = os.popen(cmd).read()
try:
respj = json.loads(resp)
print(respj['id'])
myuid_picture= respj['id']
except:
print('bad json: ', resp)
mybody = row['description'] + "\n  \n";
payload_note_put = {
"body":mybody
}
try:
resp = requests.put(url_notes_put, json=payload_note_put)
resp.raise_for_status()
resp_dict = resp.json()
print(resp_dict)
except requests.exceptions.HTTPError as e:
print("Bad HTTP status code:", e)
except requests.exceptions.RequestException as e:
print("Network error:", e)
print(nb_metadata)
print(nb_metadata_import)Voici la liste :
Fin de la liste.